A CRUD Reality
Or why your application needs the Transactional Outbox Pattern

I'm a Chilean Software Engineer living in the United Kingdom, specifically in the cold and beautiful north coast of Northern Ireland. I moved here in March 2020 -- yes, at the very start of a global pandemic! -- with my wife Briony and our cat Pua to be closer to her side of the family.
Originally a History B.A., I made the career switch around 2015 once I discovered how fun and intellectually stimulating Engineering is. Apart from building useful stuff other people can use, I love sharing what I've learned and hearing what others have learned too.
The Nasty U in CRUD
Before anything else, let's just do a quick recap on what CRUD is. CRUD stands for "Create-Read-Update-Delete" which are, in turn, the four basic operations of data storage. It's usually used as an adjective to describe a system. For instance, I often apply this acronym to describe JSON APIs which are built with frameworks that enable all four operations with little to zero boilerplate code. These usually take your input as JSON, validate it, transform it, and apply it to the database with little effort. All you have to do is to define your models, extend a particular controller, write a bit of validation and you are good to go.
The fundamental issue with this approach is that is just merely providing a JSON over HTTP interface on top of a system of record. Granted, it has some authorization and validation logic added on top, but you are still just serializing JSON into the database and back.
This is usually enough for quick prototyping or in the early stages of a system. But for a mature application, with a complex and always-evolvable domain, this approach falls short pretty quickly, and all the speed you seemed to gain by using tools that do most of the heavy lifting for you, vanishes after you try to work around the architectural limitations of such tools.
In my own opinion, a domain starts to be complex when just having an interface to store and retrieve data from the database is not enough to fulfill customers' needs. Sometimes other things apart from updating the resource in question need to happen to fulfill a requirement. In other words, the moment we start shipping features whose wording is along the lines of "when x happens in the system, x, y, and z should happen too". The more you have of these kinds of requirements, the more complex.
This is the bottom line of the issue with CRUD. Creating, reading, and deleting resources are quite straightforward operations (actually, deleting is not so much but that could be another blog post!). However, updating a resource is much more than just replacing some fields in a table. "Account updated" is not too descriptive. We need to know what exactly has changed in the account, so just saying "something was updated" is not enough. We need to be able to say "a user was deactivated", "a ticket has been archived", "an order has been shipped" or "a refund has been processed". We need to start thinking in terms of what is called "business actions" and their effects. An update is not a business action, is just something that says "Hey! Some info about this entity was changed. I don't know exactly what so go figure yourself!" We need to build this log of business actions and their effects along with the operation. We need what is often referred to as Domain Events.
Substandard Solutions
When an application reaches this point and has not been architected from the beginning to support Domain Events as a first-class citizen of the domain model, two solutions are usually implemented that in my opinion are substandard, because they don't attack the root of the problem.
Change Data Capture
The first common solution is implemented at the database level and is called Change Data Capture (CDC). The strategy consists in using the replication protocols of the data store in question to receive state changes in real time to some other process (think Meroxa or Debezium here). That process then serializes the binary information received into a more universal format (JSON) and puts it in an event stream powered by Kafka or similar technologies. The result looks a bit like this (this is taken from Meroxa PGSQL connector)
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
...
],
"optional": true,
"field": "before"
}
],
"optional": false,
"name": "resource_217"
},
"payload": {
"before": {
"id": 11,
"email": "ec@example.com",
"name": "Nell Abbott",
"birthday": "12/21/1959",
"createdAt": 1618255874536,
"updatedAt": 1618255874537
},
"after": {
"id": 11,
"email": "nell-abbott@example.com",
"name": "Nell Abbott",
"birthday": "12/21/1959",
"createdAt": 1618255874536,
"updatedAt": 1618255874537
},
"source": {
"version": "1.2.5.Final",
"connector": "postgresql",
"name": "resource-217",
"ts_ms": 1618255875129,
"snapshot": "false",
"db": "my_database",
"schema": "public",
"table": "User",
"txId": 8355,
"lsn": 478419097256
},
"op": "u",
"ts_ms": 1618255875392
}
}
The only good thing about the approach is that it doesn't need any modifications to the application source code, but that's as far as the benefits go. You still need to process the diff between the changes in your resources to figure out what was the actual domain event that occurred and extract some meaning out of it. For instance, in the example above, we can say that the email of this user was updated. Yes, you can glance at that and figure it out, but building an algorithm to do that and other changes for every entity in your system it's no easy feat.
I'm getting ahead of myself here but just imagine for a second what would be the ideal JSON you would like to work with here. I don't know about you, but I would love something along these lines (this is the actual structure from the events of one of my projects):
{
"event_id": 232,
"event_name": "user_email_changed",
"payload": {
"user_id": 11
"email": "nell-abbott@example.com"
},
"ocurred_at": 1618255874537,
"metadata": {
"performer": {
"type": "user",
"id": 11
}
}
}
Auxiliary History / Log Tables
This is another approach that is a bit suboptimal. Sometimes, in domains where historical information and audibility are essential, the need arises for some history log features. For instance, in a project management system, we want to be able to see a history tab with all the actions that have occurred on a certain ticket, when they happened, and who performed them.
What ends up happening is that some evaluator is built on top of the update operation. It analyses what fields have changed and creates a record of the change in a history table. This overcomplicated code is usually inserted in some random places after some operation has been performed. Because of this, the operation is oftentimes not inside the transactional boundary (if any!), meaning that there might be a possibility that the update is performed but the log is not. Lastly, the saddest thing is that this is a missed opportunity: is something built ad-hoc just for that entity rather than a feature of the system architecture as a whole.
Enter the Transactional Outbox Pattern
First of all, I don't like the name of Transactional Outbox Pattern. I very much prefer to call it a Transactional Event Log. Yes, the purpose of it is messaging, but also auditing.
The first requirement of the pattern is that your application stops thinking about state updates as just mere updates, and starts moving to the notion of commands. A command is an action (in imperative) that is being performed in a system. As a result of that action, the state of the system will change. Examples of commands include:
Deactivate Customer
Archive Ticket
Publish Reply
Process Shipment
Issue Refund
So whatever interface you have in the front of your application (JSON API, CLI, etc). You need to make sure you are not receiving CRUD resource representations from your clients, but rather commands. If you take a look at specifications like Smithy from AWS, you know what I'm talking about.
Once you have the command, then your corresponding service will handle it. The service will perform the necessary state updates into the relevant table, but it will also add a record in the events table about the action that has been performed. This ensures both the record and the event are persisted atomically. This is an important detail of the pattern and hence the name "Transactional": consistency is key.
You end up with a table that contains the log of events that have occurred in your system, and then the interested parties can consume those events via a REST endpoint, directly from the database or from a message queue. The consuming mechanism is pretty much your choice.
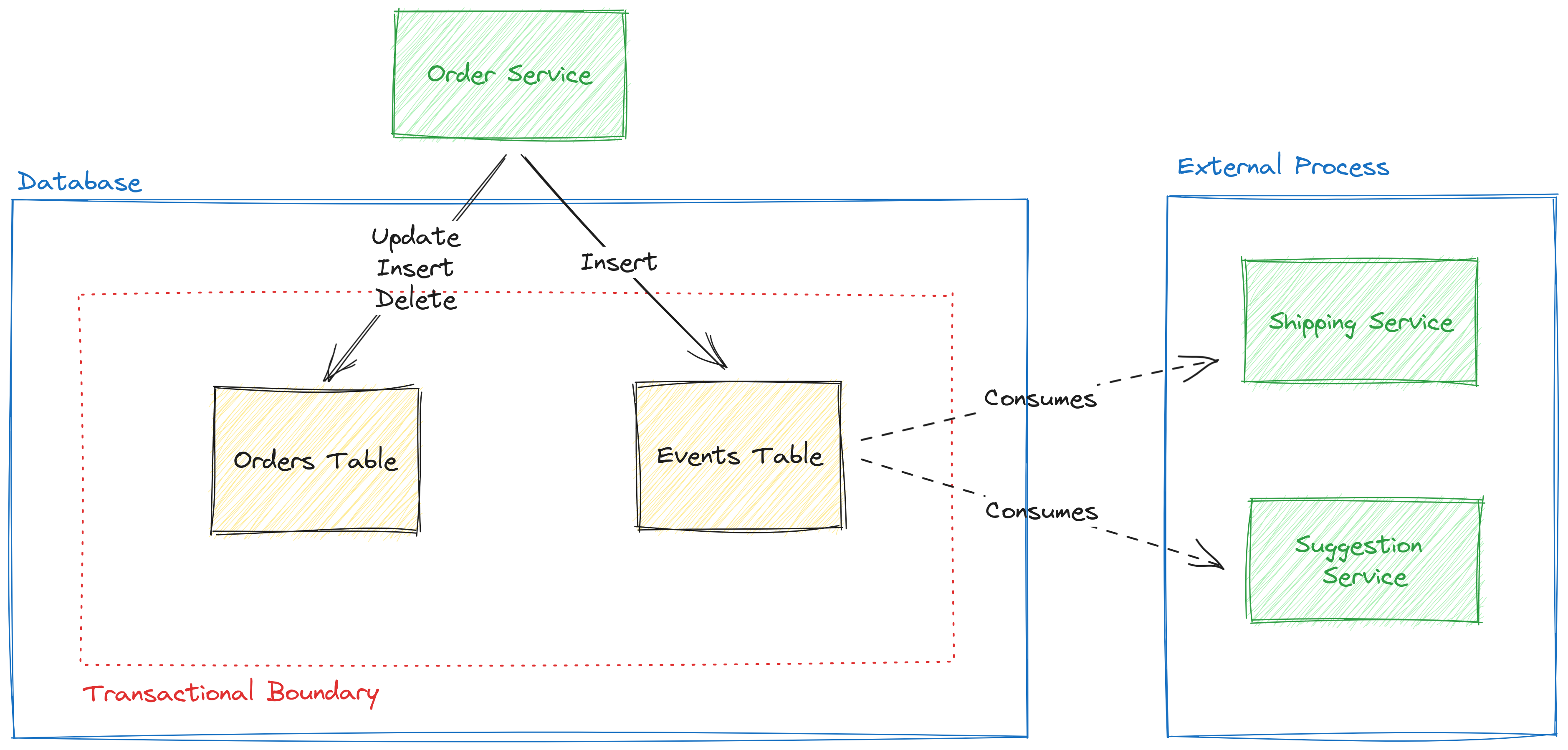
One important aspect of the events is that they carry the state relevant to the event that has occurred. As I showed in the example ideal JSON for an event a few paragraphs above, the email has changed: we include the name of the email and the user id for the email that changed. This is what Martin Fowler calls Event-Carried State Transfer: the relevant state is included in the event.
The benefit of this pattern is that now you have a log of all (and not just some) the events that have happened in your system. The log is persistent and immutable: you can read it anytime you want and share it with other systems using whatever mechanism you prefer, and other systems just need to keep track of the last event they have processed. The log is consistent: you'll never have an event that does not have its corresponding state update. And lastly, the log is really useful as a means of auditing tool or to build history-like auditing features.
A PHP Implementation
I usually implement this in PHP using Doctrine ORM and Symfony Serializer. First, let's define an interface that your application services will use:
<?php
interface EventNotifier
{
public function notify(Context \(ctx, object \)event): void;
}
Notice how the events can only be objects. Also, using a context is very useful to not pollute the method with contextual information that may or may not be there.
Then, let's suppose our application service uses it this way:
<?php
/**
* This is the event class
*/
class EmailChangedEvent
{
public function __construct(
public readonly int $userId,
public readonly string $email
) { }
}
/**
* This is the command class. This class holds the data that we need
* to fullfil this business action.
*/
class ChangeEmailCommand
{
public function __construct(
public readonly int $userId,
public readonly string $email
) { }
}
/**
* This is the command handler class.
* This class deals with the business action and notifies the events.
*/
class ChangeEmailHandler
{
public function __construct(
private readonly UserRepository $users,
private readonly EventNotifier $events,
) { }
public function __invoke(Context \(ctx, ChangeEmailCommand \)cmd): void
{
// Some data transformation and validation
\(canonicalizedEmail = Canonical::email(\)cmd->email);
Assert::email($canonicalizedEmail);
\(user = \)this->users->ofId(\(ctx, \)cmd->userId);
// The model produces the event based on the state change
\(evt = \)user->changeEmail($canonicalizedEmail);
// Here the event is notified
\(this->events->notify(\)ctx, $evt);
// The new state of user is saved
\(this->users->add(\)ctx, $user);
}
}
Both UserRepository and EventNotifier are abstractions behind an interface. Their implementation uses Doctrine under the hood, and a command bus middleware wraps this operation inside a transaction, so both the state change and the event get persisted atomically. UserRepository ofId and add methods are wrappers of findOneById and persist respectively. But let's look at the more interesting implementation of the EventNotifier with its corresponding Entity.
<?php
#[ORM\Entity]
class Event
{
#[ORM\Id, ORM\Column(type: "integer")]
public int $id = 0
public function __construct(
#[ORM\Column(type: "string")]
public string $name,
#[ORM\Column(type: "json")]
public array $payload,
#[ORM\Column(type: "json")]
public array $meta,
#[ORM\Column(type: "datetime_immutable")]
public DateTimeImmutable $ocurredAt = new DateTimeImmutable(),
) { }
}
class PersistentEventNotifier implements EventNotifier
{
public function __construct(
private readonly EntityManager $manager,
private readonly NormalizerInterface $normalizer,
private readonly EventNamer $eventNamer,
) { }
public function notify(Context \(ctx, object \)event): void
{
$ormEvent = new Event(
\(this->eventNamer->getName(\)event),
\(this->normalizer->normalize(\)event),
[
// We store the class as metadata for denormalizing the event
'php.class' => get_class($event),
// We store other metadata we are interested in
'performer' => $ctx->value('performer');
]
);
// Event is persisted
\(this->manager->persist(\)ormEvent);
}
}
The end result of this is a database table along these lines:
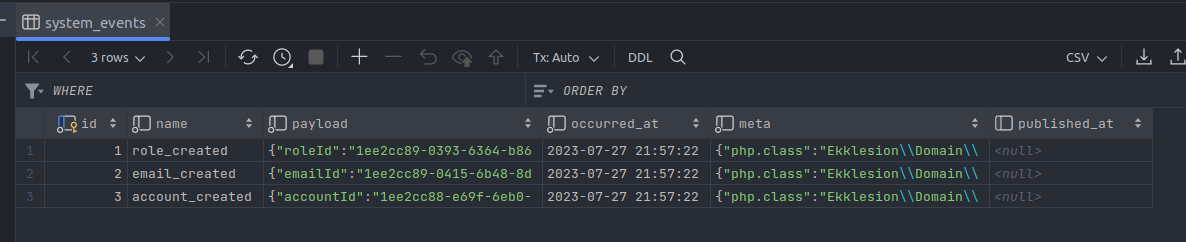
It's trivial to expose this table under a REST endpoint. In fact, I do this in one of my personal projects. Other systems that are interested in my system events can call the endpoint at their convenience to get everything that has occurred in the system. They just need to remember the last event id they have processed, and then keep on consuming from there using ?from=<id> .
There is also a published_at column for publishing the event in a message queue or a streaming platform, which is something you can do too if you wish to push these events in real-time to consumers. You can fire these events on an SSE endpoint too. I mean, there are many, many possibilities.
A Warning on Eventual Consistency
Of course, any operations you perform after the event persisted are bound to be eventually consistent. This means, because they will be asynchronous in nature they will happen, eventually, but not atomically. So if some client or consumer is waiting for that state change somewhere else, that email or that notification, the worst-case scenario may take a while to be processed. But the good this is that it will because you have an immutable log of events.
However, this is when having an event-driven system pays off because clients who are waiting for something to happen can listen to these events and react to them when they do. UI notifications using SSE are a really good pattern to mitigate the effects of eventual consistency.
A Warning on Table Size
Another drawback is the potential table size and its impact on application performance. Let me offer three pieces of advice to deal with these issues.
First, your primary key type must be an 8-byte integer, this is bigint in MySQL and bigserial in Postgres. If unsigned, you have exactly 18,446,744,073,709,551,615 max capacity for records. You are never going to use that. Even if your primary key is just 4 bytes, you have 4,294,967,295 records until your max which is quite a lot. You'll probably run out of machine storage before hitting that max.
Secondly, we all know that as a table grows, full scans are very costly. The key here is that you should never do a full scan of this table, nor correct old records with update operations. Any derived state you need from this table should be computed by doing a sequential id scan and tracking the last id processed. This is a table that is meant to be processed, not queried. If you need to query, using a process that scans the table you can denormalize its information to provide a queryable representation somewhere else (this is a process known as projection in the Event Sourcing jargon). Also, it helps if you want to index the event name and the occurred_at fields, to provide you with some leeway for querying.
Third, if for some reason you do need to query and update your records (although I advise against this), you can always resort to archiving old records, especially if you have a system that is historical in nature, with "closing" cycles like accounting or legal. In those systems, some information is never touched after a while but still needs to be kept. So you can grab a bunch of it and archive it in a secondary form of persistent storage.
Conclusion
When an application is born it usually persists state changes directly to the database and the previous state is completely discarded. However, as the application grows in complexity is convenient to have a mechanism to react to those state changes in other parts of the system or in other systems. This will avoid too much coupling in the application, since in an event-driven architecture, systems need not know who sent a particular event: they just need the event.
Implementing the Transactional Outbox Pattern solves this problem very elegantly. It integrates well with the application code and doesn't suffer from the consistency problems of sending events or jobs directly to a queue. Plus, this event log you get can be used for a multitude of purposes like auditing, event streaming, and UI notifications.



